
Schodząc konsekwentnie drabiną abstrakcji przez ostatnie tygodnie wreszcie musiał nastąpić moment, gdzie zacznie zacierać się granica między interfejsami, a szczegółową implementacją. Tym miejscem jest sam algorytm algorytmu genetycznego, czyli serce biblioteki easyGALib.
Obserwując Twittera i #dajsiepoznac, a także rozglądając się po znajomych widać, że powoli zaczyna się dokonywać selekcja wśród uczestników konkursu. Część już ma jakiś zaległy tydzień, co niektórzy już się poddali bo nie wyrabiają ze wszystkim, ale jest jeszcze znaczna grupa „dzików”, którzy jadą z tematami do przodu. Trzeba przyznać, że dzięki temu wszystkiemu konkurs nabiera rumieńców, a gdzie tam jeszcze do końca…
Wracając do tematu, jakim jest serce biblioteki easyGALib, udało się już dojść do momentu, gdzie opisywaną do tej pory abstrakcję zaczniemy przeplatać ze szczegółową implementacją. Na pierwszy ogień idzie algorytm algorytmu genetycznego, czyli właśnie centralne miejsce działania projektu.
Algorytm algorytmu genetycznego
Tutaj na wstępie, Drogi Czytelniku, muszę przyznać, że schemat działania algorytmu genetycznego podany w jednym z pierwszych postów nie do końca mi się spodobał po ponownym wgłębieniu się w temat. Po drobnym wywiadzie (jak kto woli riserczu), okazuje się że jest to bardzo szczególny przypadek działania i nie bardzo nadaje się do stworzenia abstrakcji. W zamian zaproponuję więc nieco bardziej uogólniony schemat, na podstawie którego będziemy w stanie zaimplementować serce biblioteki easyGALib:
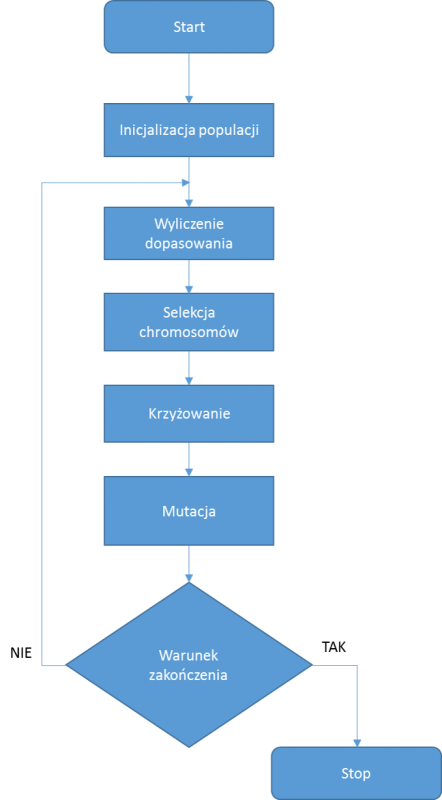
Wygląda to trochę lepiej, prawda? Nie mamy tu jakiś zagadkowych 90% populacji spełniających dopasowanie, tylko jasne polecenia i zdefiniowany przez nas warunek zakończenia działania algorytmu.
Serce biblioteki easyGALib
Możemy więc przejść do samej implementacji powyższego schematu w bibliotece. Nie ma tutaj większej filozofii w zasadzie. Całość umieszczona jest w klasie GABase, która to będzie podstawą dla szczegółowych przypadków algorytmów genetycznych, które zależą od tego w jaki sposób będzie w nich reprezentowany gen. Kod prezentuje się więc następująco:
public IGAResult Execute(IGeneticAlgorithmInput input)
{
long generation = 0;
PopulationInit();
while (!IsFinalGeneration(generation))
{
CalculateFitness();
SelectChromosomes();
Crossover();
Mutate();
generation++;
}
return new GAResult() { BestChromosome = GetBestChromosome()};
}
Widzimy tutaj jedynie bazowe funkcje, w miejsce których pojawią się szczegółowe implementacje każdej z nich. Największym wyzwaniem będzie tutaj maksymalne wykorzystanie funkcji bazowej i przeniesienie do abstrakcyjnych metod tylko bardzo konkretnych zadań, zależnych od rodzaju chromosomu, na którym operujemy.
Było to pierwsze starcie moje starcie z teorią samego algorytmu genetycznego w projekcie i celowo tutaj nie rozpisywałem się nad szczegółami jego działania. Wkrótce będziemy przechodzić przez każdą z metod po kolei i tam już będzie większe pole do popisu jeżeli chodzi o wykorzystanie w kodzie czysto naukowej wiedzy.
Dodaj komentarz